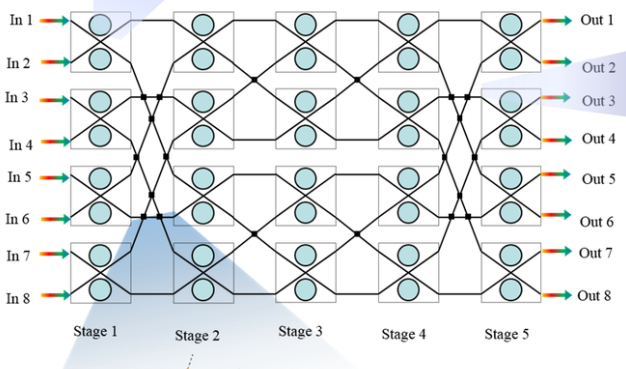
About Me

Noor Ul Huda Ajmal
I am a
I am a Software Engineering graduate with massive interest in Data Space. As an freelance ML Engineer, I am helping clients to design, develop, and deploy machine learning solutions that address complex business problems and generate value for the organization. I am skilled in Tableau, Power BI and python tools for data insights.